Overview of single-cell analysis in R/Bioconductor
Stephanie Hicks
intro-single-cell.RmdOverview
Key resources
- Workshop material: pkgdown website
- Code: GitHub
Part 1
Learning objectives
- Understand how count matrices are created from single-cell experimental platforms and protocols
- Recognize which basic principles and concepts were transferred from bulk to single-cell data analyses
- Understand the key differences between bulk and single-cell data
- Define what is a “Unique Molecular Identifier”
- Define multiplexing (and demultiplexing)
- Overview of basics in single-cell data analyses including quality control, normalization, feature selection, dimensionality reduction, and clustering
Part 2
Learning objectives
- Be able to create a single-cell count matrix and read it into R
- Recognize and define the
SingleCellExperimentS4 class in R/Bioconductor to store single-cell data
Overview
NGS data from scRNA-seq experiments must be converted into a matrix of expression values.
This is usually a count matrix containing the number of reads (or UMIs) mapped to each gene (row) in each cell (column). Once this quantification is complete, we can proceed with our downstream statistical analyses in R.
Constructing a count matrix from raw scRNA-seq data requires some thought as the term “single-cell RNA-seq” encompasses a variety of different experimental protocols. This includes
- droplet-based protocols like 10X Genomics, inDrop and Drop-seq
- plate-based protocols with UMIs like CEL-seq(2) and MARS-seq
- plate-based protocols with reads (mostly Smart-seq2)
- others like sciRNA-seq, etc
Each approach requires a different processing pipeline to deal with cell demultiplexing and UMI deduplication (if applicable). Here, we will briefly describe some of the methods used to generate a count matrix and read it into R.
Creating a count matrix
As mentioned above, the exact procedure for quantifying expression depends on the technology involved:
- For 10X Genomics data, the
Cellrangersoftware suite (Zheng et al. 2017) provides a custom pipeline to obtain a count matrix. This uses STAR to align reads to the reference genome and then counts the number of unique UMIs mapped to each gene. - Alternatively, pseudo-alignment methods such as
alevin(Srivastava et al. 2019) can be used to obtain a count matrix from the same data. This avoids the need for explicit alignment, which reduces the compute time and memory usage. - For other highly multiplexed protocols, the
scPipepackage provides a more general pipeline for processing scRNA-seq data. This uses the Rsubread aligner to align reads and then counts reads or UMIs per gene. - For CEL-seq or CEL-seq2 data, the
scruffpackage provides a dedicated pipeline for quantification. - For read-based protocols, we can generally re-use the same pipelines for processing bulk RNA-seq data (e.g. Subread, RSEM, salmon)
- For any data involving spike-in transcripts, the spike-in sequences should be included as part of the reference genome during alignment and quantification.
In all cases, the identity of the genes in the count matrix should be defined with standard identifiers from Ensembl or Entrez. These provide an unambiguous mapping between each row of the matrix and the corresponding gene.
In contrast, a single gene symbol may be used by multiple loci, or the mapping between symbols and genes may change over time, e.g., if the gene is renamed.
This makes it difficult to re-use the count matrix as we cannot be confident in the meaning of the symbols.
(Of course, identifiers can be easily converted to gene symbols later on in the analysis. This is the recommended approach as it allows us to document how the conversion was performed and to backtrack to the stable identifiers if the symbols are ambiguous.)
SingleCellExperiment Class
One of the main strengths of the Bioconductor project lies in the use of a common data infrastructure that powers interoperability across packages.
Users should be able to analyze their data using functions from different Bioconductor packages without the need to convert between formats.
To this end, the SingleCellExperiment class (from the
SingleCellExperiment package) serves as the common currency
for data exchange across 70+ single-cell-related Bioconductor
packages.
This class implements a data structure that stores all aspects of our single-cell data - gene-by-cell expression data, per-cell metadata and per-gene annotation - and manipulate them in a synchronized manner.
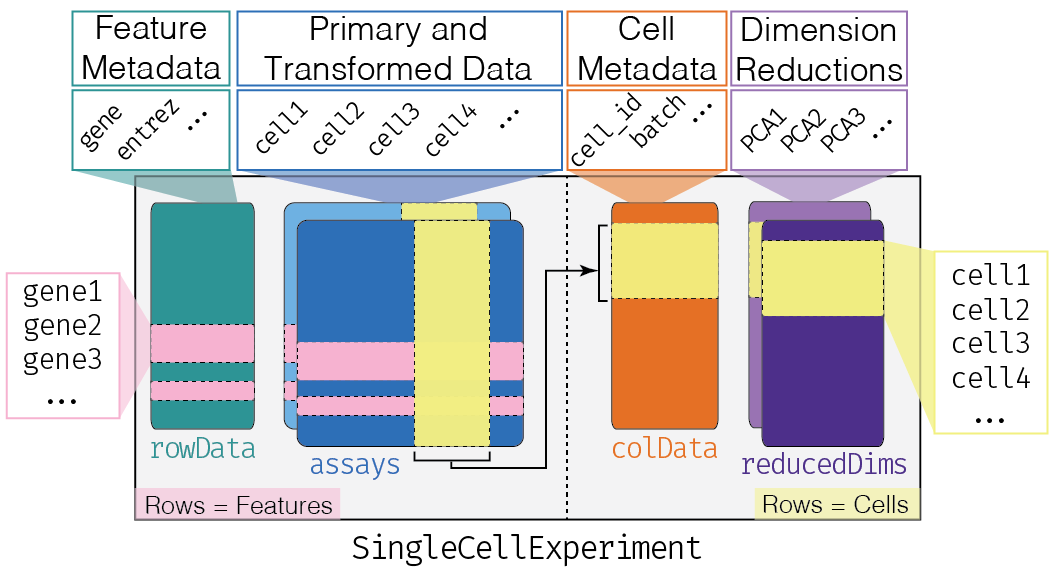
[Amezquita et al. 2019 (https://doi.org/10.1101/590562)]
- Each piece of (meta)data in the
SingleCellExperimentis represented by a separate “slot”.
(This terminology comes from the S4 class system, but that’s not important right now).
If we imagine the SingleCellExperiment object to be a
cargo ship, the slots can be thought of as individual cargo
boxes with different contents, e.g., certain slots expect
numeric matrices whereas others may expect data frames.
If you want to know more about the available slots, their expected formats, and how we can interact with them, check out this chapter.
SingleCellExperiment Example
Let’s show you what a SingleCellExperiment (or
sce for short) looks like.
sce## class: SingleCellExperiment
## dim: 20006 3005
## metadata(0):
## assays(1): counts
## rownames(20006): Tspan12 Tshz1 ... mt-Rnr1 mt-Nd4l
## rowData names(1): featureType
## colnames(3005): 1772071015_C02 1772071017_G12 ... 1772066098_A12
## 1772058148_F03
## colData names(10): tissue group # ... level1class level2class
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(2): ERCC repeatThis SingleCellExperiment object has 20006 genes and
3005 cells.
We can pull out the counts matrix with the counts()
function and the corresponding rowData() and
colData():
counts(sce)[1:5, 1:5]## 1772071015_C02 1772071017_G12 1772071017_A05 1772071014_B06
## Tspan12 0 0 0 3
## Tshz1 3 1 0 2
## Fnbp1l 3 1 6 4
## Adamts15 0 0 0 0
## Cldn12 1 1 1 0
## 1772067065_H06
## Tspan12 0
## Tshz1 2
## Fnbp1l 1
## Adamts15 0
## Cldn12 0
rowData(sce)## DataFrame with 20006 rows and 1 column
## featureType
## <character>
## Tspan12 endogenous
## Tshz1 endogenous
## Fnbp1l endogenous
## Adamts15 endogenous
## Cldn12 endogenous
## ... ...
## mt-Co2 mito
## mt-Co1 mito
## mt-Rnr2 mito
## mt-Rnr1 mito
## mt-Nd4l mito
colData(sce)## DataFrame with 3005 rows and 10 columns
## tissue group # total mRNA mol well sex
## <character> <numeric> <numeric> <numeric> <numeric>
## 1772071015_C02 sscortex 1 1221 3 3
## 1772071017_G12 sscortex 1 1231 95 1
## 1772071017_A05 sscortex 1 1652 27 1
## 1772071014_B06 sscortex 1 1696 37 3
## 1772067065_H06 sscortex 1 1219 43 3
## ... ... ... ... ... ...
## 1772067059_B04 ca1hippocampus 9 1997 19 1
## 1772066097_D04 ca1hippocampus 9 1415 21 1
## 1772063068_D01 sscortex 9 1876 34 3
## 1772066098_A12 ca1hippocampus 9 1546 88 1
## 1772058148_F03 sscortex 9 1970 15 3
## age diameter cell_id level1class level2class
## <numeric> <numeric> <character> <character> <character>
## 1772071015_C02 2 1 1772071015_C02 interneurons Int10
## 1772071017_G12 1 353 1772071017_G12 interneurons Int10
## 1772071017_A05 1 13 1772071017_A05 interneurons Int6
## 1772071014_B06 2 19 1772071014_B06 interneurons Int10
## 1772067065_H06 6 12 1772067065_H06 interneurons Int9
## ... ... ... ... ... ...
## 1772067059_B04 4 382 1772067059_B04 endothelial-mural Peric
## 1772066097_D04 7 12 1772066097_D04 endothelial-mural Vsmc
## 1772063068_D01 7 268 1772063068_D01 endothelial-mural Vsmc
## 1772066098_A12 7 324 1772066098_A12 endothelial-mural Vsmc
## 1772058148_F03 7 6 1772058148_F03 endothelial-mural VsmcPart 3
Learning objectives
- Be able to describe a standard workflow for analyzing single-cell data
- Be able to run code for a standard workflow starting from loading a
SingleCellExperimentin R and identifying clusters.
Overview
Here, we provide an overview of the framework of a typical scRNA-seq analysis workflow:
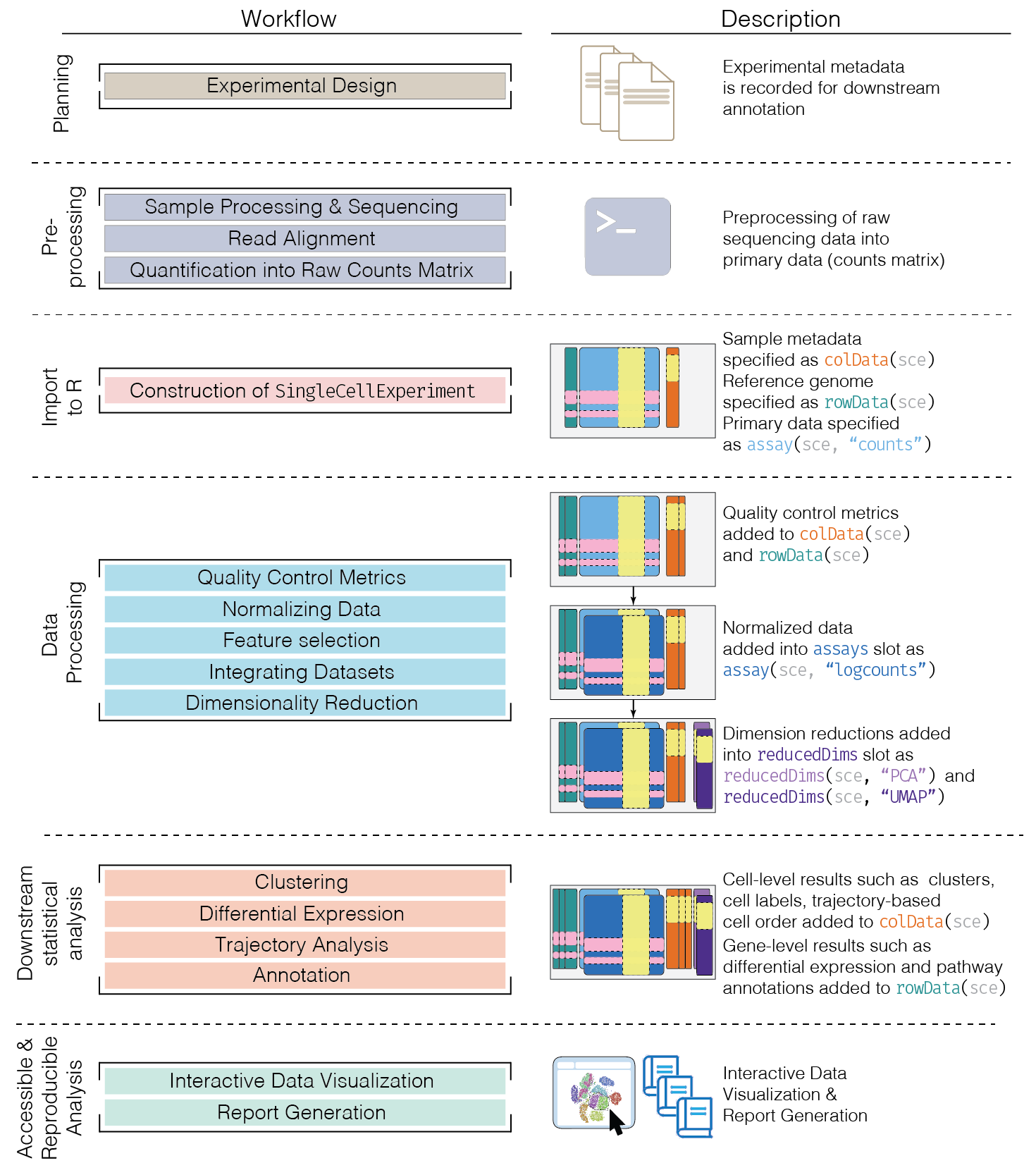
In the simplest case, the workflow has the following form:
- We compute quality control metrics to remove low-quality cells that would interfere with downstream analyses. These cells may have been damaged during processing or may not have been fully captured by the sequencing protocol. Common metrics includes the total counts per cell, the proportion of spike-in or mitochondrial reads and the number of detected features.
- We convert the counts into normalized expression values to eliminate cell-specific biases (e.g., in capture efficiency). This allows us to perform explicit comparisons across cells in downstream steps like clustering. We also apply a transformation, typically log, to adjust for the mean-variance relationship.
- We perform feature selection to pick a subset of interesting features for downstream analysis. This is done by modelling the variance across cells for each gene and retaining genes that are highly variable. The aim is to reduce computational overhead and noise from uninteresting genes.
- We apply dimensionality reduction to compact the data and further reduce noise. Principal components analysis is typically used to obtain an initial low-rank representation for more computational work, followed by more aggressive methods like \(t\)-stochastic neighbor embedding for visualization purposes.
- We cluster cells into groups according to similarities in their (normalized) expression profiles. This aims to obtain groupings that serve as empirical proxies for distinct biological states. We typically interpret these groupings by identifying differentially expressed marker genes between clusters.
Quick start (simple)
Here, we use the a droplet-based retina dataset from Macosko et
al. (2015), provided in the scRNAseq package. This starts
from a count matrix and finishes with clusters in preparation for
biological interpretation. We also demonstrate how to identify
differentially expressed genes between the clusters.
library(scRNAseq)
sce <- MacoskoRetinaData()
# Quality control (using mitochondrial genes).
library(scater)
is.mito <- grepl("^MT-", rownames(sce))
qcstats <- perCellQCMetrics(sce, subsets=list(Mito=is.mito))
filtered <- quickPerCellQC(qcstats, percent_subsets="subsets_Mito_percent")
sce <- sce[, !filtered$discard]
# Normalization.
sce <- logNormCounts(sce)
# Feature selection.
library(scran)
dec <- modelGeneVar(sce)
hvg <- getTopHVGs(dec, prop=0.1)
# PCA.
library(scater)
set.seed(1234)
sce <- runPCA(sce, ncomponents=25, subset_row=hvg)
# Clustering.
library(bluster)
colLabels(sce) <- clusterCells(sce, use.dimred='PCA',
BLUSPARAM=NNGraphParam(cluster.fun="louvain")) 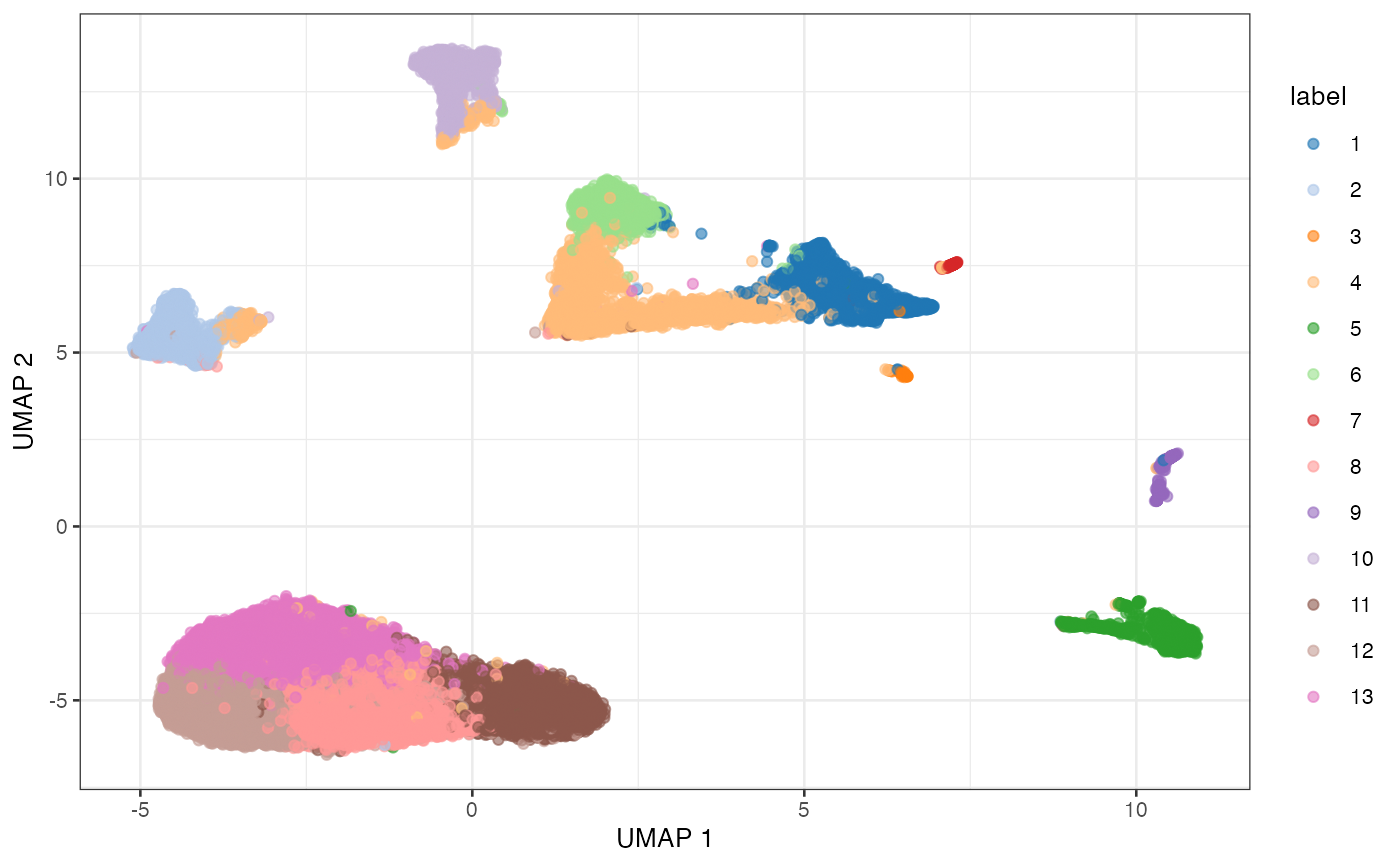
UMAP plot of the retina dataset, where each point is a cell and is colored by the assigned cluster identity.
# Marker detection (between pairs of groups)
markers <- findMarkers(sce, test.type="wilcox", direction="up", lfc=1)
length(markers)## [1] 13
markers[[1]]## DataFrame with 24658 rows and 16 columns
## Top p.value FDR summary.AUC AUC.2
## <integer> <numeric> <numeric> <numeric> <numeric>
## MEG3 1 0.00000e+00 0.00000e+00 0.867306 0.857315
## TUBA1A 1 3.58784e-81 5.89793e-78 0.609195 0.479862
## SNHG11 1 0.00000e+00 0.00000e+00 0.737419 0.747343
## SYT1 2 3.51850e-268 1.08449e-264 0.786614 0.454677
## CALM1 2 0.00000e+00 0.00000e+00 0.812019 0.665619
## ... ... ... ... ... ...
## VSIG1 24654 1 1 0 0
## GM16390 24655 1 1 0 0
## GM25207 24656 1 1 0 0
## 1110059M19RIK 24657 1 1 0 0
## GM20861 24658 1 1 0 0
## AUC.3 AUC.4 AUC.5 AUC.6 AUC.7 AUC.8
## <numeric> <numeric> <numeric> <numeric> <numeric> <numeric>
## MEG3 0.6814265 0.463403 0.806255 0.478814 0.1822596 0.888640
## TUBA1A 0.1162662 0.315768 0.422655 0.289249 0.4529957 0.541010
## SNHG11 0.0822847 0.562474 0.741261 0.703891 0.0228628 0.742098
## SYT1 0.5354274 0.317921 0.786614 0.307464 0.0591646 0.549534
## CALM1 0.1535742 0.370682 0.715928 0.425258 0.0105809 0.791806
## ... ... ... ... ... ... ...
## VSIG1 0 0 0 0 0 0
## GM16390 0 0 0 0 0 0
## GM25207 0 0 0 0 0 0
## 1110059M19RIK 0 0 0 0 0 0
## GM20861 0 0 0 0 0 0
## AUC.9 AUC.10 AUC.11 AUC.12 AUC.13
## <numeric> <numeric> <numeric> <numeric> <numeric>
## MEG3 0.850705 0.48570145 0.866916 0.873796 0.867306
## TUBA1A 0.509171 0.33506617 0.552997 0.566389 0.609195
## SNHG11 0.745361 0.74450392 0.737413 0.744927 0.737419
## SYT1 0.823158 0.39904104 0.575948 0.584176 0.633476
## CALM1 0.444978 0.00587859 0.749949 0.834002 0.812019
## ... ... ... ... ... ...
## VSIG1 0 0 0 0 0
## GM16390 0 0 0 0 0
## GM25207 0 0 0 0 0
## 1110059M19RIK 0 0 0 0 0
## GM20861 0 0 0 0 0Session Info
## R version 4.2.1 (2022-06-23)
## Platform: aarch64-apple-darwin21.6.0 (64-bit)
## Running under: macOS Monterey 12.5.1
##
## Matrix products: default
## BLAS: /opt/homebrew/Cellar/openblas/0.3.21/lib/libopenblasp-r0.3.21.dylib
## LAPACK: /opt/homebrew/Cellar/r/4.2.1_2/lib/R/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] bluster_1.6.0 scran_1.24.0
## [3] scRNAseq_2.10.0 scater_1.24.0
## [5] ggplot2_3.3.6 scuttle_1.6.3
## [7] SingleCellExperiment_1.18.0 SummarizedExperiment_1.26.1
## [9] Biobase_2.56.0 GenomicRanges_1.48.0
## [11] GenomeInfoDb_1.32.3 IRanges_2.30.1
## [13] S4Vectors_0.34.0 BiocGenerics_0.42.0
## [15] MatrixGenerics_1.8.1 matrixStats_0.62.0
##
## loaded via a namespace (and not attached):
## [1] AnnotationHub_3.4.0 BiocFileCache_2.4.0
## [3] systemfonts_1.0.4 igraph_1.3.4
## [5] lazyeval_0.2.2 BiocParallel_1.30.3
## [7] digest_0.6.29 ensembldb_2.20.2
## [9] htmltools_0.5.3 viridis_0.6.2
## [11] fansi_1.0.3 magrittr_2.0.3
## [13] memoise_2.0.1 ScaledMatrix_1.4.0
## [15] cluster_2.1.4 limma_3.52.2
## [17] Biostrings_2.64.1 pkgdown_2.0.6
## [19] prettyunits_1.1.1 colorspace_2.0-3
## [21] blob_1.2.3 rappdirs_0.3.3
## [23] ggrepel_0.9.1 textshaping_0.3.6
## [25] xfun_0.32 dplyr_1.0.10
## [27] crayon_1.5.1 RCurl_1.98-1.8
## [29] jsonlite_1.8.0 glue_1.6.2
## [31] gtable_0.3.1 zlibbioc_1.42.0
## [33] XVector_0.36.0 DelayedArray_0.22.0
## [35] BiocSingular_1.12.0 scales_1.2.1
## [37] edgeR_3.38.4 DBI_1.1.3
## [39] Rcpp_1.0.9 viridisLite_0.4.1
## [41] xtable_1.8-4 progress_1.2.2
## [43] dqrng_0.3.0 bit_4.0.4
## [45] rsvd_1.0.5 metapod_1.4.0
## [47] httr_1.4.4 ellipsis_0.3.2
## [49] farver_2.1.1 pkgconfig_2.0.3
## [51] XML_3.99-0.10 uwot_0.1.14
## [53] sass_0.4.2 dbplyr_2.2.1
## [55] locfit_1.5-9.6 utf8_1.2.2
## [57] labeling_0.4.2 tidyselect_1.1.2
## [59] rlang_1.0.5 later_1.3.0
## [61] AnnotationDbi_1.58.0 munsell_0.5.0
## [63] BiocVersion_3.15.2 tools_4.2.1
## [65] cachem_1.0.6 cli_3.3.0
## [67] generics_0.1.3 RSQLite_2.2.16
## [69] ExperimentHub_2.4.0 evaluate_0.16
## [71] stringr_1.4.1 fastmap_1.1.0
## [73] yaml_2.3.5 ragg_1.2.2
## [75] knitr_1.40 bit64_4.0.5
## [77] fs_1.5.2 purrr_0.3.4
## [79] KEGGREST_1.36.3 AnnotationFilter_1.20.0
## [81] sparseMatrixStats_1.8.0 mime_0.12
## [83] xml2_1.3.3 biomaRt_2.52.0
## [85] compiler_4.2.1 rstudioapi_0.14
## [87] beeswarm_0.4.0 filelock_1.0.2
## [89] curl_4.3.2 png_0.1-7
## [91] interactiveDisplayBase_1.34.0 statmod_1.4.37
## [93] tibble_3.1.8 bslib_0.4.0
## [95] stringi_1.7.8 highr_0.9
## [97] GenomicFeatures_1.48.3 desc_1.4.1
## [99] lattice_0.20-45 ProtGenerics_1.28.0
## [101] Matrix_1.4-1 vctrs_0.4.1
## [103] pillar_1.8.1 lifecycle_1.0.1
## [105] BiocManager_1.30.18 jquerylib_0.1.4
## [107] RcppAnnoy_0.0.19 BiocNeighbors_1.14.0
## [109] bitops_1.0-7 irlba_2.3.5
## [111] httpuv_1.6.5 rtracklayer_1.56.1
## [113] R6_2.5.1 BiocIO_1.6.0
## [115] promises_1.2.0.1 gridExtra_2.3
## [117] vipor_0.4.5 codetools_0.2-18
## [119] assertthat_0.2.1 rprojroot_2.0.3
## [121] rjson_0.2.21 withr_2.5.0
## [123] GenomicAlignments_1.32.1 Rsamtools_2.12.0
## [125] GenomeInfoDbData_1.2.8 parallel_4.2.1
## [127] hms_1.1.2 grid_4.2.1
## [129] beachmat_2.12.0 rmarkdown_2.16
## [131] DelayedMatrixStats_1.18.0 shiny_1.7.2
## [133] ggbeeswarm_0.6.0 restfulr_0.0.15